# node - 爬虫初体验
# 背景介绍
# 爬虫
爬虫,也叫网络蜘蛛(spider),是一种用来自动浏览万维网的网络机器人。是搜索引擎的重要组成部分,搜索引擎通过爬虫来更新自身的网站内容或其对其它网站的索引。搜索引擎将爬虫所访问的页面保存下来,然后生成索引供用户搜索。
# robots.txt 协议
robots.txt 是一个文本文件,告诉搜索引擎的爬虫,网站中的哪些内容是不应被爬虫爬取的,哪些内容是可以被爬取的,爬虫就会按照文件中的内容来确定访问范围。比如 Disallow /login, /admin 这些涉及用户敏感信息的路径,就可以告诉爬虫,这些路径是禁止爬取的(律师函警告)。
所以,当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,搜索蜘蛛将能尝试访问网站上所有的页面。
robots.txt 放在网站的根目录下。
这个协议不是规范,只是个约定。
爬虫应该应该在不影响目标站点运行的情况下进行爬取。
基本写法
【User-agent】
爬虫种类,可以使用通配符 *,表示所欲的搜索机器人
User-agent: *
百度的搜索机器人
User-agent: Baiduspider
【Disallow】
不允许爬取的目录
下面代码表示禁止爬寻admin目录下面的目录
Disallow: /admin/
下面代码表示禁止抓取网页所有的.jpg格式的图片
Disallow: /.jpg$
下面代码表示禁止爬取ab文件夹下面的adc.html文件
Disallow: /ab/adc.html
下面代码表示禁止访问网站中所有包含问号 (?) 的网址
Disallow: /*?*
下面代码表示禁止访问网站中所有页面
Disallow: /
【Allow】 下面代码表示允许访问以".html"为后缀的URL
Allow: .html$
下面代码表示允许爬寻tmp的整个目录
Allow: /tmp
截图 豆瓣的 robots.txt

# 爬虫的基本流程
主要针对网站内容的爬取
- 在不影响目标站点运行的情况下,进行爬取
- 抓取数据
- 存储数据
- 渲染数据
下面以掘金 (opens new window)上看到的抓取 豆瓣电影热映影片 为栗。
# 抓取数据
目录结构
截图 简单的目录结构
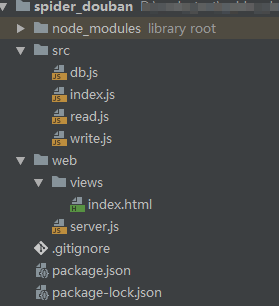
.
├─ src // 抓取数据
│ ├─ db.js // 数据库操作
│ ├─ index.js
│ ├─ read.js
│ └─ write.js
├─ web // 渲染数据
│ ├─ views
│ │ └─ index.html
│ └─ server.js
└─ package.json // 项目依赖
2
3
4
5
6
7
8
9
10
11
获取内容
根据前端后端交互的区别,这里分为两种情况
单页面应用 页面主要通过 ajax 请求数据之后进行渲染。现在搜索引擎的蜘蛛还不能有效爬取这种网站的内容,所以一般的内容网站都不得采用这种方式。这种网站的数据抓取相对轻松,只要 f12 找到 api,需要的数据就基本已经获取到了。也可是使用一些代理抓包工具来查看接口,如 Fiddler/Charles。
服务端渲染 页面在服务端基本渲染好了,访问的时候直接返回的 html 代码。这种网站就需要先爬取然后解析。
其实就是通过请求 url ,获取到页面的 html 代码,然后从 html 里面获取数据,可以把 html 转化为 DOM 来获取,也可以正则匹配。
这里使用 request 或者加强版 request-promise 来请求,cheerio 来转化 html 代码。
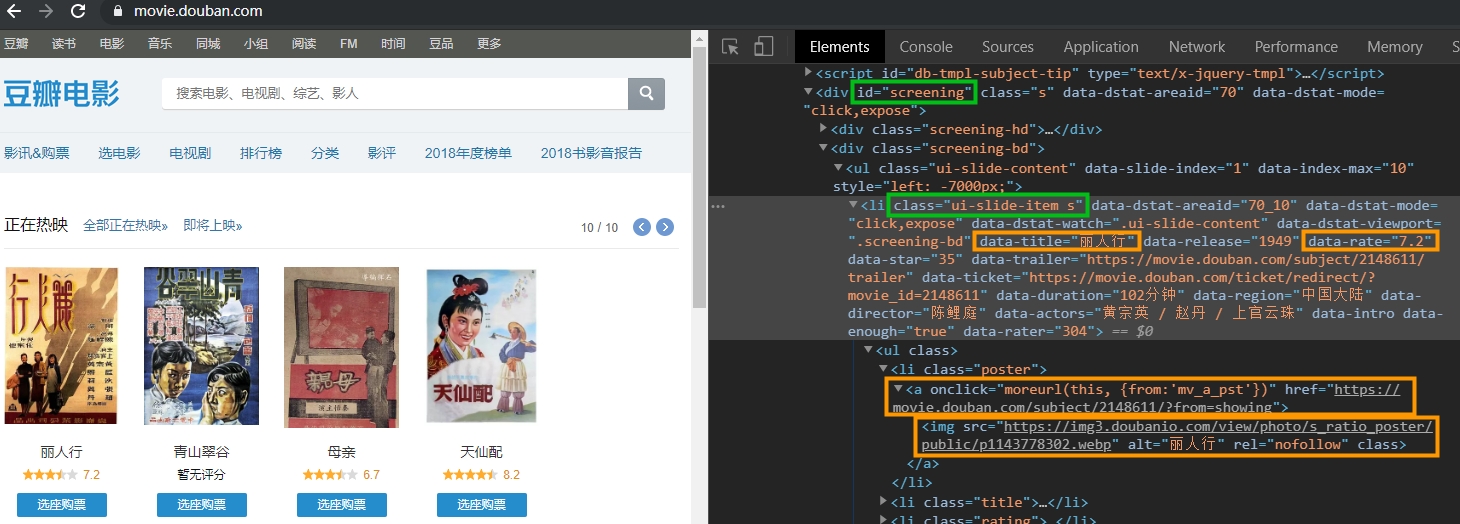
然后,通过观察豆瓣电影页面,正在热映模块的 DOM 结构,找到读取内容的方法
// 引入请求库
const rp = require('request-promise');
// 用来把 html 转化为 DOM
const cheerio = require('cheerio');
const opts = {
url: 'https://movie.douban.com'
};
rp(opts).then(res =>{
// res 就是目标页面请求回来的 html 代码
// load 返回的是一个类似 jq 的对象,操作 DOM 也和完全按照 jq 的方式。
const $ = cheerio.load(res);
let result = []; // 结果数组
// 定位到 正在热映电影 模块
$('#screening li.ui-slide-item').each((index, item) => {
let ele = $(item);
// 获取 名称|评分|地址|封面|id
let name = ele.data('title');
let score = ele.data('rate') || '暂无评分';
let href = ele.find('.poster a').attr('href');
let image = ele.find('img').attr('src');
let id = href && href.match(/(\d+)/)[1];
if (!name || !image || !href) return;
result.push({
name,
score,
href,
image,
id
});
});
return result;
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
总结
- 通过
request-promise获取 html 代码cheerio将 html 转化成 DOM- 操作 DOM 获取需要的电影数据(名称|评分|地址|封面|id)
- 返回包含所有电影数据的数组
# 存储数据
获取到了数据,就要把数据存储起来,方便后期处理和使用。也是爬虫最主要的目的,好不容易获取到了当然要存起来。
这里选择 mongodb 。
- 安装 mongodb;
- 启动 mongodb 服务;
- 数据库连接
const mongoose = require('mongoose');
/**
* 数据库连接
*/
const config = {
db: 'mongodb://localhost/movie_douban',
options: {
poolSize: 50,
auto_reconnect: true,
}
};
const database = app => {
// mongoose.set('debug', true);
// 连接数据库
mongoose.connect(config.db, config.options);
// 连接中断重连
mongoose.connection.on('disconnected', (err) => {
console.error(err);
mongoose.connect(config.db);
});
// 连接错误
mongoose.connection.on('error', err => {
console.error(err);
});
// 连接成功
mongoose.connection.on('open', async () => {
console.log('Connected to mongoose');
});
};
database();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
- 定义 Schema
const mongoose = require('mongoose');
/**
* 定义电影字段
*/
const Schema = mongoose.Schema;
const MovieSchema = new Schema({
name: String,
score: String,
href: String,
image: String,
id: Number
});
MovieSchema.statics = {
// 获取
async getMovie (id) {
const movie = await this.findOne({
id: id
}).exec();
if (movie) console.log('数据库查询到movie', id, movie.name);
else console.log('数据库查询movie', id, '没有');
return movie;
},
// 保存
async saveMovie (data) {
let id = +data.id;
let movie = await this.getMovie(id);
if (movie) {
// 更新
movie = await this.update({ id }, movie);
} else {
// 保存
movie = await this.create(data);
}
return movie;
},
async getMovieQuery (query) {
let movies = await this.find(query).exec();
if (!movies) return [];
return movies;
}
};
// 获取movie的数据模型
const Movie = mongoose.model('Movie', MovieSchema);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
- 写入数据库
const mongoose = require('mongoose');
// 获取movie的数据模型
const Movie = mongoose.model('Movie');
const write = async (movies) => {
for (let movie of movies) {
// 通过 saveMovie 保存或者更新电影
await Movie.saveMovie(movie);
}
};
2
3
4
5
6
7
8
9
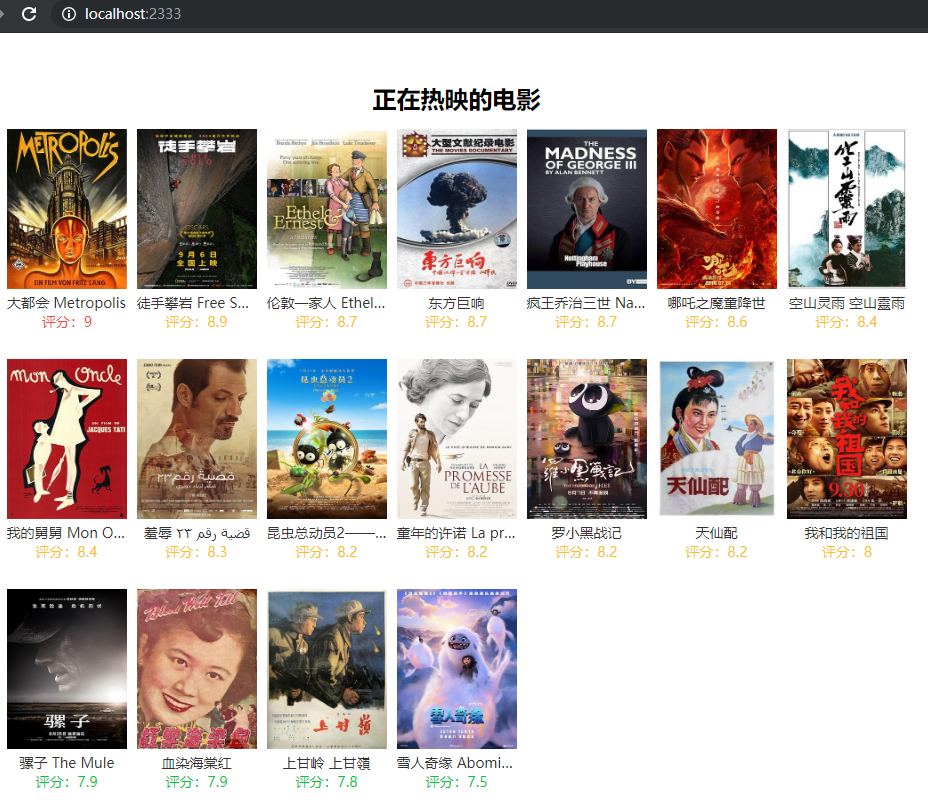
# 渲染数据
提供一个出口,把爬取到的数据展示出来。拿到了数据就可以随便玩儿了。
这里使用 express + ejs 渲染。
ejs 模板 //index.html
<!DOCTYPE html>
<html lang="zh-cn">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<meta name="referrer" content="no-referrer">
<title>热映的电影</title>
<style>
</style>
</head>
<body>
<div class="container">
<h2 class="caption">正在热映的电影</h2>
<ul class="list">
<% for(let i=0;i < movies.length; i++){
let movie = movies[i];
%>
<li>
<a href="<%=movie.href%>" target="_blank">
<img src="<%=movie.image%>"/>
<p class="title"><%=movie.name%></p>
<p class="score <%= movie.scoreClass %>">评分:<%=movie.score%></p>
</a>
</li>
<% } %>
</ul>
</div>
</body>
</html>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
server.js
const express = require('express');
const mongoose = require('mongoose');
const path = require('path');
const database = require('../src/db');
const app = express();
// 连接数据库
database();
const Movie = mongoose.model('Movie');
// 设置模板引擎
app.set('view engine', 'html');
app.set('views', path.join(__dirname, 'views'));
app.engine('html', require('ejs').__express);
// 首页路由
app.get('/', async (req, res) => {
let movies = await Movie.getMovieQuery({});
res.render('index', {
movies: movies.filter(i => {
let score = parseFloat(i.score);
i.score = score;
if (score >= 9) {
i.scoreClass = 'c-1';
} else if (score >= 8) {
i.scoreClass = 'c-2';
} else {
i.scoreClass = 'c-3';
}
// 评分大于 7.5 的才返回
return score && score >= 7.5;
}).sort((a, b) => b.score - a.score)
});
});
app.listen(2333);
console.log('app start at http://localhost:2333');
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
最终效果图
# 反爬虫
主要介绍4种。
非浏览器检查 浏览器发起的请求,在请求头里面都携带各种信息,比如
User-Agent。而直接在服务端发起的请求是不会携带。识别 Headers 里面没有包含 User-Agent。限制 IP 同一 IP 短时间内过于频繁的访问。按照用户的访问行为进行限制,比如一秒钟内限制5次请求,1小时500次请求。超过次数就限制 ip 的访问。
弹验证码 检测到异常访问的时候,弹出验证码,验证是人为行为还是机器访问。 栗子:google 搜索
限制登录 限制页面需要登录后才可以访问,同一账号登录后请求过于频繁,采取封号的行为来限制。
# 防反爬虫
针对前面提到的反爬虫策略进行调整方案。
- 非浏览器检查 请求头里面没有 User-Agent ,那就设置一个。 request-promise 代码示例
const rp = require('request-promise');
const opts = {
url: 'https://movie.douban.com',
headers:{
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.75 Safari/537.36'
}
};
rp(opts).then(res=>console.log(res));
2
3
4
5
6
7
8
9
- 限制 IP 为了短时间的获得多的数据,只能高频率的访问。所以只能使用代理来进行访问,访问次数临近上限的时候就更换代理服务器。 可选的方案一般有:
- 免费代理:度娘一下,有很多提供免费代理服务器的网站。但是可用率一般比较低。
- 付费代理:可以购买一下付费的代理服务服务器。可用率据说会高一点,因为要给钱,没用过。
- 代理池:就是多找几个免费代理,爬取更多的免费代理来使用。
- ADSL 拨号代理:使用 ADSL 拨号主机搭建http请求代理的服务。据说比较稳定,还是要花钱,没用过。 搭建方法可以参考 (opens new window)
使用代理服务器进行请求的栗子:
const rp = require('request-promise');
const opts = {
url: 'https://movie.douban.com',
proxy: 'http://代理服务器ip:端口'
};
rp(opts).then(res=>console.log(res));
2
3
4
5
6
7
弹验证码 验证码分为非常多种,如普通图形验证码、算术题验证码、滑动验证码、点触验证码、手机验证码、扫二维码等。 对于普通图形验证码,可以使用 OCR 识别。 其他的,简单方便的话可以对接收费的打码平台。
限制登录 限制了登录就莫得办法咯。
- 同样的数据,找一下不需要的接口来获取。
- 维护 Cookies ,使用批量账号模拟登录,请求的时候随机带上 Cookies。 rp 官网栗子
const rp = require('request-promise');
const tough = require('tough-cookie');
// Easy creation of the cookie - see tough-cookie docs for details
// 使用 tough-cookie 创建一个类 cookie 对象
let cookie = new tough.Cookie({
key: "some_key",
value: "some_value",
domain: 'api.mydomain.com',
httpOnly: true,
maxAge: 31536000
});
// Put cookie in an jar which can be used across multiple requests
// 把 cookie 放在 rp 的请求配置里,所有的请求都会带上 cookie
let cookiejar = rp.jar();
cookiejar.setCookie(cookie, 'https://api.mydomain.com');
// ...all requests to https://api.mydomain.com will include the cookie
let options = {
uri: 'https://api.mydomain.com/...',
jar: cookiejar // Tells rp to include cookies in jar that match uri
};
rp(options)
.then(function (body) {
// Request succeeded...
})
.catch(function (err) {
// Request failed...
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 优化
- 多进程
- 控制并发
# 最后
所有分享仅用于技术学习。